
Reliability Decision Tree for Critical Infrastructure
How much redundancy should you implement to support your critical ICT infrastructure. This is a common question when making decisions regarding the design of redundant and robust ICT systems, networks, and their supporting power, cooling and facility infrastructure. The reliability decision tree outlined below has been incorporated into the ANSI/BICSI 002 Data Center Design and Operations standard, which simplify the process into four simple steps. This methodology can be used to help guide design decisions for the:
Application Architecture
ICT Systems (servers, storage)
Network Architecture and Topology
Network Cabling Infrastructure
Power Distribution and Backup Energy Sources
Cooling Systems
Security Systems and Policies
Structural Robustness to withstand external forces
Step 1: Determine Operational Requirements The first step in defining the risk level associated with a mission-critical ICT service is to define the intended operational requirements. Sufficient resources must be available to achieve an acceptable level of quality over a given time period. ICT functions that have a high-quality expectation over a longer time period are by definition more critical than those requiring less resources, lower quality or are needed over a shorter time period. The key element to consider here is time, which is quantified as "windows of opportunity" for testing and maintenance. Thus, to define the operational requirements for a critical ICT service, assign one of five operational levels, as defined in the table below. Note that the term "shutdown" means that all ICT service operations has ceased and is not able to perform its intended function during that time. Shutdown does not refer to the loss of discrete systems or components if they do not disrupt the ability of the critical ICT service to continue its mission.

Now a common response is that ICT services can never be taken offline for maintenance. That is often the case, but not always. Some examples of organizations that may have opportunities for planned maintenance activities include:
Manufacturing: Some manufacturing have mandatory shut downs to retool their machines and processes. During this time critical infrastructure may be able to have a planned shutdown without impacting the critical ICT services required to support the manufacturing processes.
Education: Critical ICT systems supporting K-12 or Higher Education campuses may have opportunities to schedule planned shut downs during extended breaks. This may be acceptable as long as the ICT systems included in the planned shut down are not required to support security, voice, email or instant messaging that are critical during emergency event responses.
Step 2: Determine Availability Requirements
The second step in the risk management process is to identify the ICT services availability requirements, which is defined as the total uptime that the ICT services must meet. In this step, the availability refers only to scheduled uptime; that is, the time during which the ICT services are actually expected to function.
We express this availability in terms of an Availability Ranking. The rank selected for a given ICT service is chosen as the intersection between a level of intended availability (typically expressed in 9's) and the operational level identified in Step 1. Since a function or process that has a high availability requirement with a low operational level has less risk associated with it than a similar function with a higher operational level, we use this step to adjust the overall availability to reflect the true functional requirement. This step will result in one of five Availability Rankings to be used in Step 3.
Note: the table below expresses availability either in:
Annual allowable maximum downtime in minutes
As a percentage of up-time expressed in 9's

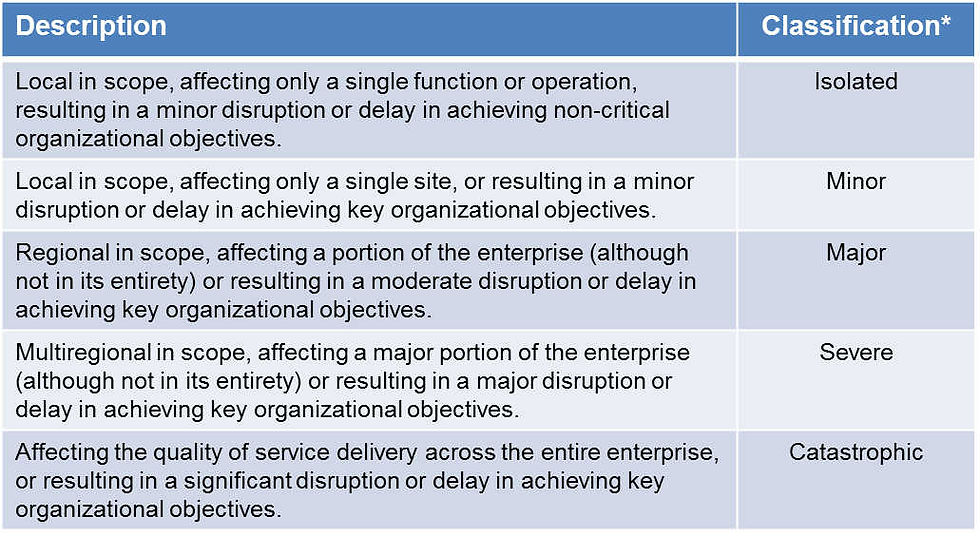
Step 3: Determine Impact of Downtime The third step in the risk management process is to identify the impact or consequences of downtime. This is an essential component of risk management because not all downtime has the same impact on critical ICT services. Identifying the impact of downtime on critical ICT services helps determine the tactics that are recommended to be deploy in order to mitigate downtime risk. As shown in the table below, there are five impact classifications, each associated with a specific impact scope.
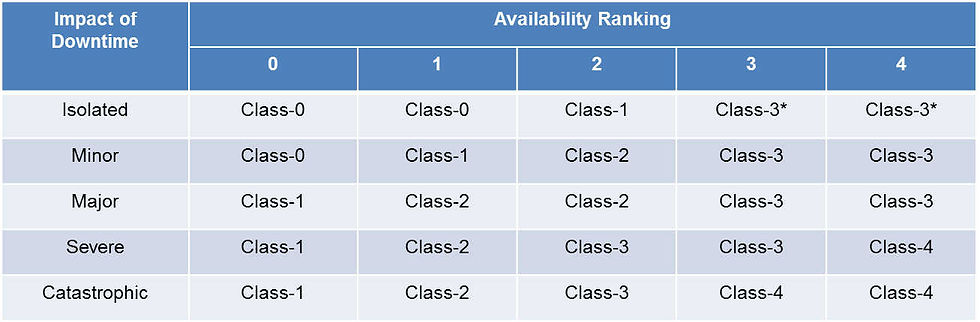
Step 4: Determine Facility Reliability Class The final step in the process is to combine the three previously identified factors to arrive at a usable expression of required robustness. This expression is used as a guide to determine the redundancy and reliability features needed to appropriately support critical ICT services. Since the operational level is subsumed within the availability ranking (per Step 2), the task at hand is to matrix the availability ranking against the impact of downtime and arrive at an appropriate Class of ICT services. The table below shows how this is done:
In my next post I will outline the unique performance characteristics for each of these classes and those performance characteristics help guide design decisions regarding the ICT services, systems and supporting critical infrastructure.
